下面对ALBEF网络进行简单的介绍,ALBEF是Align before Fuse的缩写,其是在融合前对齐并用动量蒸馏的办法进行视觉和语言的表示学习。
多模态学习有什么下游任务,比如:
- 文本-图像检索
- 图像问答
- 多模态推理
图像和文本多模态主要有3个部分组成:
- 图像编码器
- 文本编码器
- 融合编码器
其可以根据各自的比重分为4种结构。
其中ALBEF模型左侧是12层的图片编码器,而右侧是6层的文本编码器,通过提取特征后计算余弦相似度及图片与文本对比loss。
ALBEF借鉴了MoCo的思想引入了动量模型,其既有图片Embedding的参数也有文本Embedding的参数。
以下是其网络结构图:
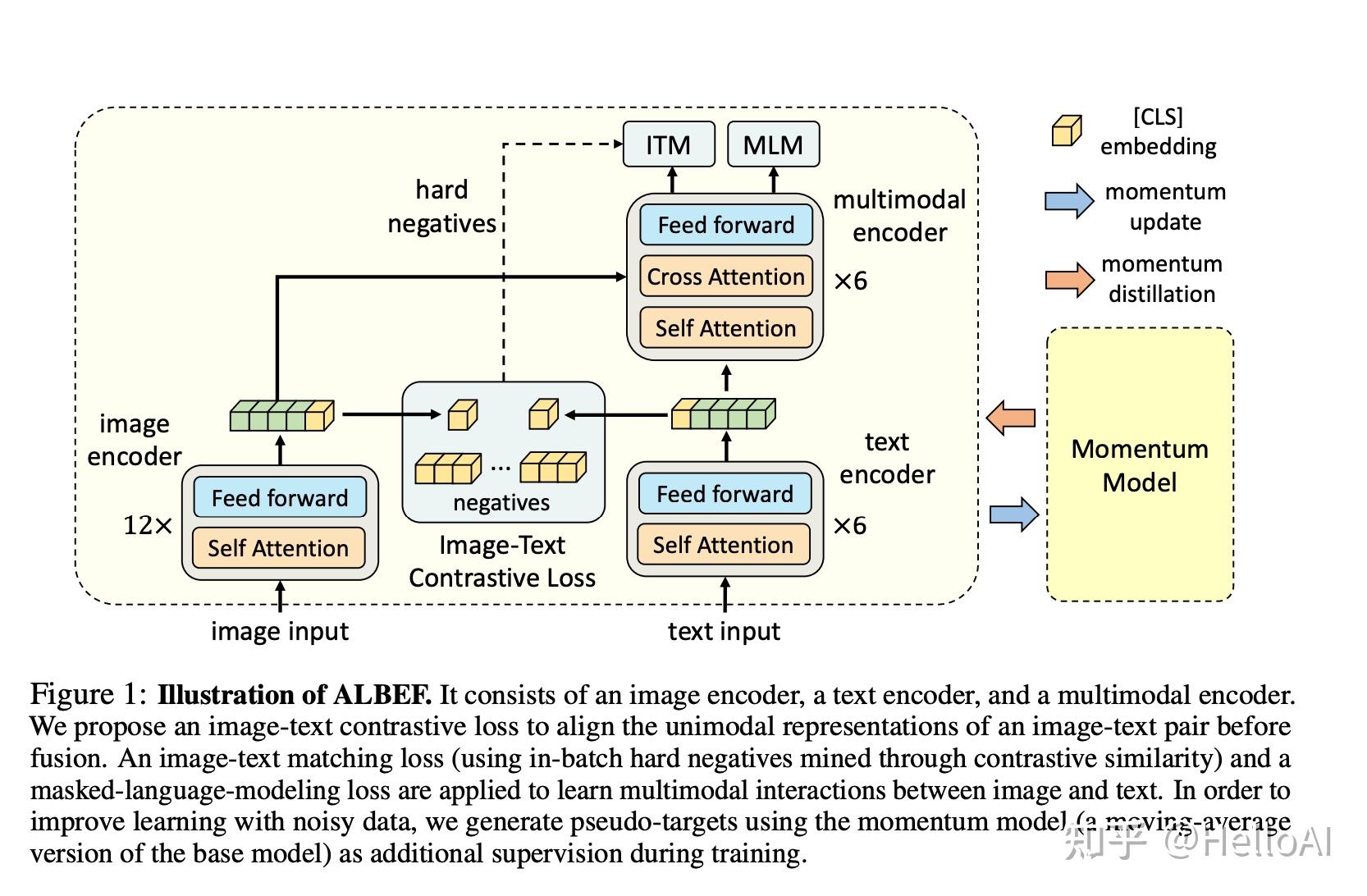
可以看到,其融合部分,其在文本编码器6层的基础上又增加了6层,其中包括Cross Attention。而query来自文本编码器,K,V来自图片编码器的输出。
ITM用于文本与图片匹配任务,其是二分类的,MLM用于带掩码的语言模型,用于预测被遮住的标签是什么。
在ALBEF模型中有3个loss,分别为ITC、ITM及MLM的Loss。另外其还提出了动量蒸馏的概念。
参考视频:
如果喜欢这篇文章或对您有帮助,可以:[☕] 请我喝杯咖啡 | [💓] 小额赞助

