BLIP是Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation中首字母的组合,即通过自举方式预训练的语言-图像模型,它统一了视觉-文本的理解和生成。
它与之前ALBEF的同一个作者,因此其继承后者的很多思想。其解决了2个问题:
- 训练1个模型既可以做检索又可以做生成
- 解决网络收集图文对数据中的噪声问题
怎么设计一种网络结构既可以有编码器又可以有解码器,可以同时做图文检索又可以做基于图片的文本生成任务。
下面是其网络结构:
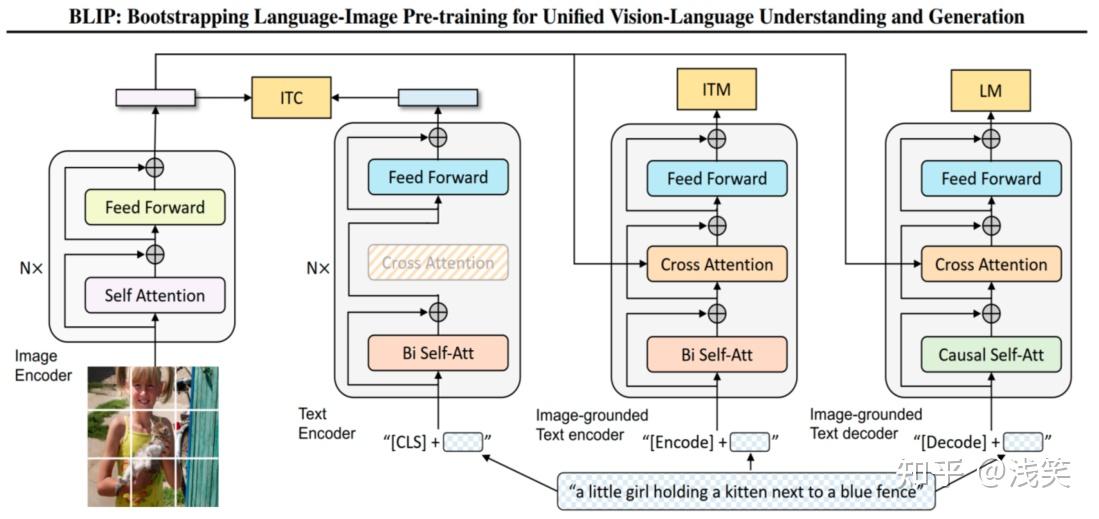
其中左侧是基于ViT结构的图像编码器,最终获取图像的特征。接着是标准ITC任务架构,也是CLIP采用的架构。其是由一个图像编码器和单模态文本编码器构成。
之后是标准ITM网络架构,其是由图像编码器和多模态文本编码器组成。最后是基于多模态文本解码器的LM架构。
BLIP将上述3个模型同时进行训练,但部分参数是共享的。每个batch训练时,图像编码器训练时前向传播1次,单模态文本编码器、多模态文本编码器和多模态文本解码器分别在文本前面添加不同任务的token,各自前向传播1次。而同一个颜色模块和共享的参数是一样的。
对于互联网噪声数据,BLIP使用预训练的多模态解码器来判断图文是否匹配。训练的数据包含两部分,包括网络采集的图文对(质量较差)以及人工标注的图文对(质量较好)从而预训练1个模型。之后用ITC和ITM在人工标注的高质量数据集上训练1个Filter模型。同时运用上述这2个数据集训练1个Captioner模型。
参考视频:
如果喜欢这篇文章或对您有帮助,可以:[☕] 请我喝杯咖啡 | [💓] 小额赞助

