一般的神经网络模型只能预测固定的类型从而造成难迁移的问题。CLIP网络通过对比学习(图文配对)实现自监督学习。
以下是CLIP的网络结构:
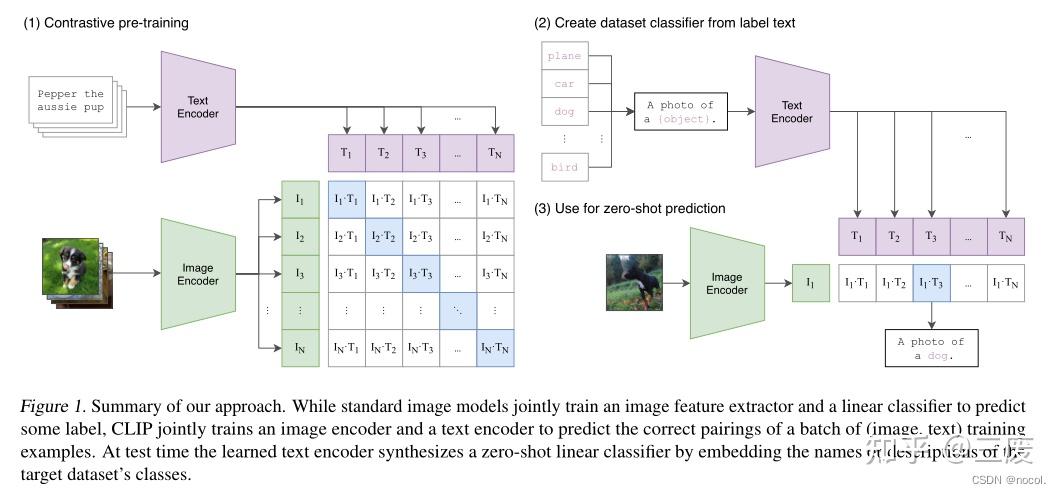
其中文本通过1个Text Encoder,而图片通过1个Image Encoder分别得到文本向量表示和图片向量表示。再通过一个线性投射层,投射在一个多模态向量空间中,尽量拉近配对文本与图片的向量距离,而不配对的文本与图片向量尽可能的远。
实验发现在模型深度、宽度及图像分辨率上同时增加计算量,模型提升比仅在一个维度增加计算力要好。其损失函数一般为InfoNCE。
而模型推理时先从数据集分类器中创建标签文本,然后就可以使用zero-shot进行预测。
而相关利用CLIP的分割任务可以参考LSeg及GroupViT。
参考视频:
https://www.bilibili.com/video/BV1pYmDYgEDW/ https://www.bilibili.com/video/BV1hwLEzZEnS?p=17 https://blog.csdn.net/jiaoyangwm/article/details/132252010
如果喜欢这篇文章或对您有帮助,可以:[☕] 请我喝杯咖啡 | [💓] 小额赞助

