简述
在正式介绍UNet与DeepLab网络架构之前,先对其整个过程进行简单的梳理。
需要注意的是,U-Net、UNet++、UNet+++分别由3个不同团队提出的,是基于前者网络结构上的改进。相比而言,DeepLab系列是Google核心团队主导的统一迭代演进模型。
另外UNet网络系列是纯正的Encoder-Decoder结构,而DeepLab v1-v3仅有Encoder,直到DeepLab v3+时才引入Decoder。
UNet网络框架
U-Net
U-Net最初通过卷积网络解决医学中图像分割问题,由于该网络结构非常简单而得到广泛的应用。其通过基础卷积层+对称编解码+跳跃连接的设计,解决了医学图像分割中三个核心问题:
- 小样本训练: 依靠数据增强弥补训练数据不足的问题
- 器官/病变边界模糊: 利用跳跃连接skip-connection融合多尺度特征,保留细节信息
- 计算资源受限: 无冗余设计,整个网络没有使用全连接层、批量归一化(BN)或Dropout等复杂技术,从而减少了参数量。
其网络架构如下图所示:
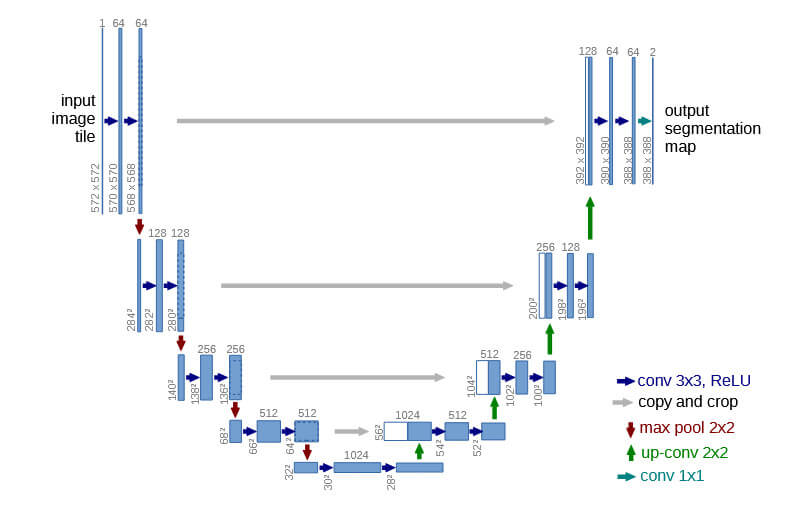
从上图可以看出,使用的仅是3x3卷积与ReLU的基础块,而下采样通过2x2最大池化来实现,上采样通过2x2转置卷积或插值法进行实现。最后输出层使用1x1卷积将通道数映射为类别数。
UNet++
U-Net虽然网络结构非常简单,但是存在如下一些问题:
- 直接使用skip-connection将编码器的浅层特征与解码器深层特征进行拼接,而两者语义信息存在显著差异,从而导致直接融合效果受限
- 网络需要预先设定固定深度,但不同任务(如不同尺寸的病变分割)所需的最优深度不同,从而限制了模型的适应性
而UNet++通过如下改进设计解决上述问题:
- 嵌套密集跳跃连接:通过在编码器与解码器之间引入多级子网络,形成稠密连接路径。而每一层解码器接收所有同尺度及更浅层的编码器特征,从而实现渐进式特征融合,减少语义差异并增强尺度信息传递
- 自适应网络剪枝:可在推理阶段移除部分子网络分支,从而平衡精度与速度的要求
其网络结构如下图所示:
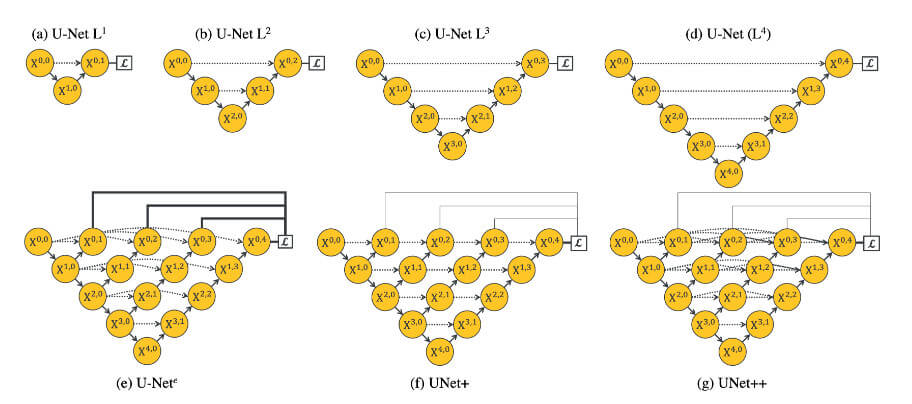
在上图中,每个节点代表一个卷积块,向下的箭头代表下采样,而向上的箭头代表上采样,点状箭头代表跳跃连接(skip connections)。 其借鉴了DenseNet密集连接的思想,在Encoder和Decoder之间跳跃路径上,跳跃路径上的每一个节点都接收前面所有更浅层节点的特征图,并将其拼接起来作为输入。
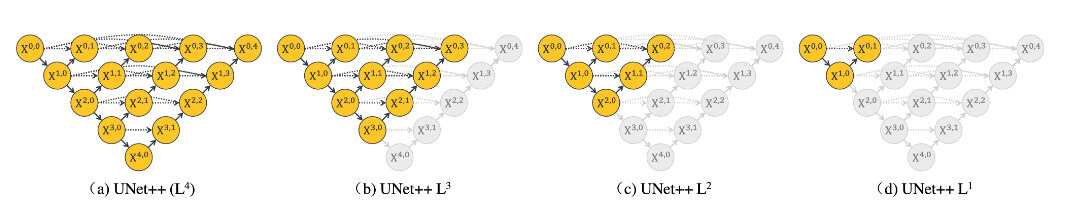
而在推理时可以根据业务需求进行剪枝:
UNet+++
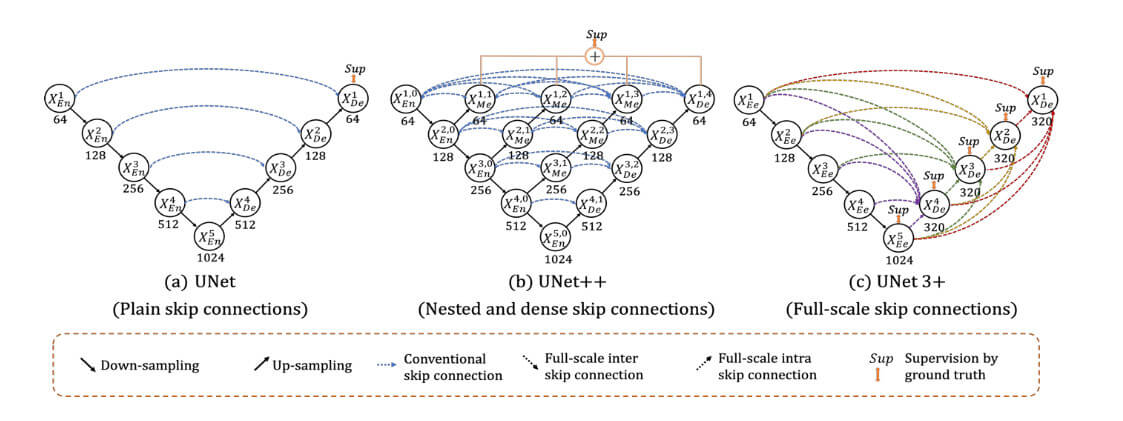
相比UNet++仅嵌套融合同层级特征,导致跨尺度信息交互不足的问题。在UNet 3+提出了全尺度跳跃连接(Full-Scale Skip Connections)的概念,通过Decoder每层直接融合Encoder所有层级(包括浅、中、深层)的特征图,通过跳跃连接实现跨分辨率特征融合,从而增强小目标检测能力。
其网络结构如下所示:
DeepLab网络框架
相比U-Net系列,DeepLab系列引入空洞卷积,在不牺牲分辨率情况下扩大了感受野。本质上DeepLab是FCN(Fully Convolutional Network)架构改进的变体。
DeepLab v1
传统CNN网络中存在这样的问题,最后的全连接层会限制输入的尺寸并。而将全连接层FC移除后,将其全部替换为卷积层,从而使得网络可接受任意尺寸输入并可输出同尺寸热力图。
下面是其网络结构:
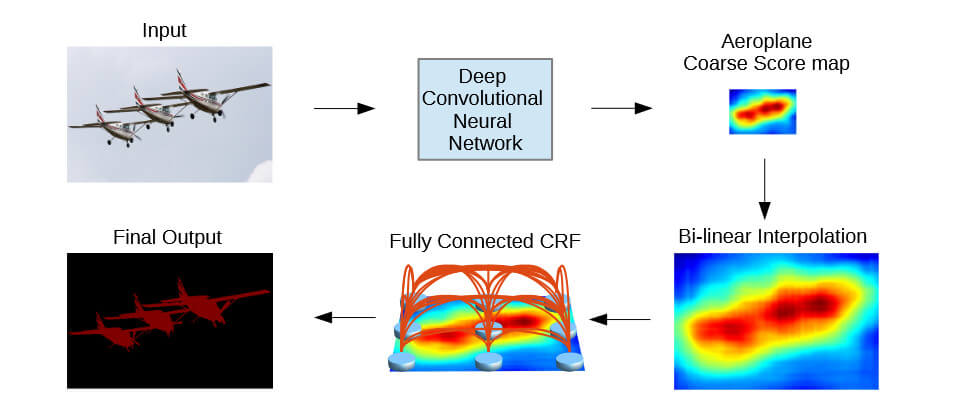
可以看到输入图片经过深度卷积神经网络后得到对应分数图,再经过双线性插值进行上采样,最后通过全连接CRF层改进其最终输出。
DeepLab v2
由于DeepLab v1存在如下多尺度分割问题:
- 物体尺寸差异大,由于单一空洞卷积感受野固定,难以覆盖不同尺度目标
- 深层特征偏向大物体,丢失小目标。
因此在DeepLab v2中引入ASPP(Atrous Spatial Pyramid Pooling)模块,通过并行使用不同空洞率(如rates=6,12,18,24)的卷积层捕捉多尺度上下文信息。如下图所示:
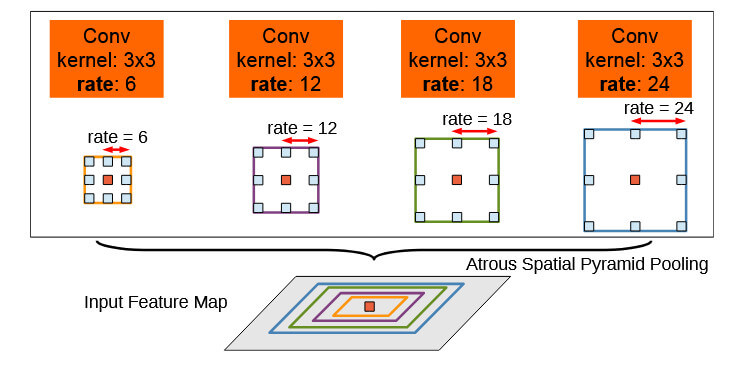
另外DeepLab v2中将主干网络由VGG16升级为ResNet101,提升高层语义表达能力并支持更高效训练。
DeepLab v3
由于DeepLab v2继承之前版本的CRF模块从而造成计算瓶颈,而在DeepLab v3中移除了该模块从而实现纯卷积架构。
另外由于ASPP不同空洞率分支感受野重叠严重问题,在v3中引入1x1卷积和全局平均池化分支,通过补充局部与全局上下文信息,缓解空洞卷积边界栅格效应。
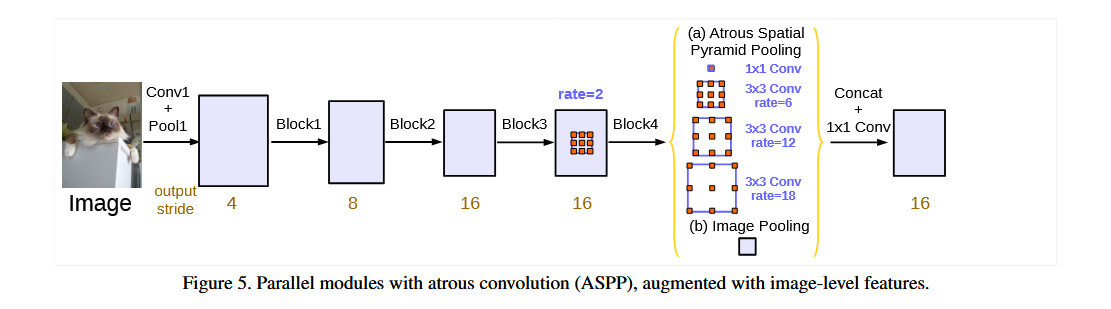
DeepLab v3+
DeepLab v3+为了解决v3中直接8倍或16倍采样导致边界模糊导致的物体轮廓断裂、小目标分割精度低的问题,新增了轻量级Decoder模块。
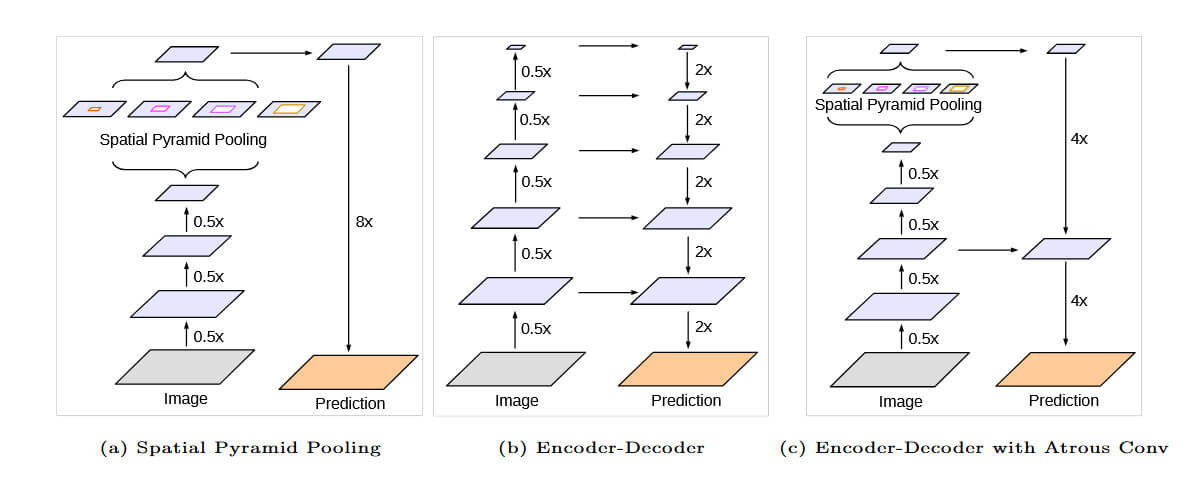
另外将主干网络从ResNet升级为Xception。
可以看到整个DeepLab结构变动并不是很大。
代码实现
最后说完理论上网络结构的变化,下面提供相应代码的实现:
- DeepLab官方基于TensorFlow的实现deeplab
- DeepLab v3的PyTorch实现DeepLabV3Plus-Pytorch或直接使用TorchVision中的模型
- U-Net的PyTorch实现unet
- UNet++的实现pytorch-nested-unet及segmentation-models-pytorch
- UNet++的PyTorch实现UNet-3-Plus-Pytorch

