实际上arXiv平台上论文只是初稿,并没有经过同行的评审,因此其可信度需要结合实验复现、论文引用量及作者团队背景综合判断其可信度。不过这种深度一般需要研究生学历才会接触到,但实际上本科生稍加学习也是可以应对的。
一般来说,这些论文单词量并不会很大,CET-4基本可以应付。重要的是信心,不要胆怯,而且论文中很多想法实际上你也是可以想到的。在阅读论文时,要带着问题,即本次你想从这篇论文中学习到什么。比如想看下它说的是什么,或者想看下它的网络结构是怎样设计的。每次阅读一部分,逐次蚕食吸收,自然有所成就。 一般而言,每篇论文开头都会介绍相关的背景,比如之前有什么类似的技术,而这些技术得到了怎样的效果或有什么缺点。之后就开始进入自己内容的介绍,介绍的想法、网络结构,有什么优势,解决怎样的问题。最后自然是使用的数据集、训练参数、训练结果的展现以及细节的叙述。就比如这段内容:
TTS is a typical one-to-many mapping problem, since multiple possible speech sequences can correspond to a text sequence due to different variations in speech audio, such as pitch, duration,sound volume and prosody. In autoregressive TTS, the decoder can condition on the text sequence and the previous mel-spectrograms to predict next mel-spectrograms, where the previous mel-spectrograms can provide some variation information and thus alleviate this problem to a certain degree. While in non-autoregressive TTS, the only input information is text which is not enough to fully predict the variance in speech. In this case, the model is prone to overfit to the variations of the target speech in the training set, resulting in poor generalization ability.
自己的翻译是:
TTS是典型的一对多映射问题,因为一个文本序列由于不同变化(音高、时长、音量和韵律)可以对应多种可能语音序列。在自回归TTS中,解码器可以以文本序列作为条件,通过之前的梅尔频谱预测下一个梅尔频谱,其中之前的梅尔频谱可以提供一些变体信息从而在一定程序上缓解这一问题。而在非自回归TTS中,输入的信息只有文本,它是不足以完全预测语音中的变化。在这种情况下,模型容易拟合训练集目标语音的变化,结构泛化较差。
而DeepSeek的翻译如下:
文本到语音(TTS)是一个典型的一对多映射问题。由于语音音频中存在音高、时长、音量和韵律等多种可变因素,同一文本序列可能对应多个不同的语音序列。在自回归TTS模型中,解码器可以通过文本序列和前一时间步的梅尔频谱图来预测后续频谱,其中历史梅尔频谱提供了部分变化信息,从而在一定程度上缓解了这一问题。而在非自回归TTS模型中,仅有文本输入信息不足以完整预测语音的所有动态变化。这种情况下,模型容易过度拟合训练数据中的语音变化特征,导致泛化能力显著下降。
阅读论文没必要做到100%都翻译正确,掌握大概的意思即可。毕竟语言之间的鸿沟,在深度神经网络盛行的今天,已经区别不是那么大了。如果可以话,可以借助一些翻译工具。
这里以FastSpeech作为例子进行说明,其paper分别为:
- FastSpeech: Fast, Robust and Controllable Text to Speech
- FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
首先从其编号1905和2006可以看出这两篇文章分别发布在19年5月和20年6月。从其标题可以看出,FastSpeech是一种快速、鲁棒和可控的文本到语音合成。而FastSpeech2是快速高质量端到端文本到语音合成。
其中FastSpeech有5个版本,而FastSpeech2有8个版本,一般我们选择最新版本进行阅读即可。在这里主要是为了获取其网络结构,然后编写代码进行实现。
首先对比其网络结构,下面是FastSpeech的结构:
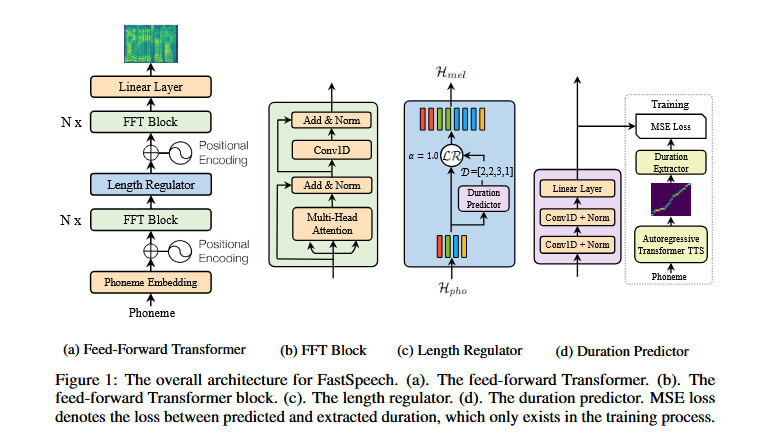
之后是FastSpeech2的结构:
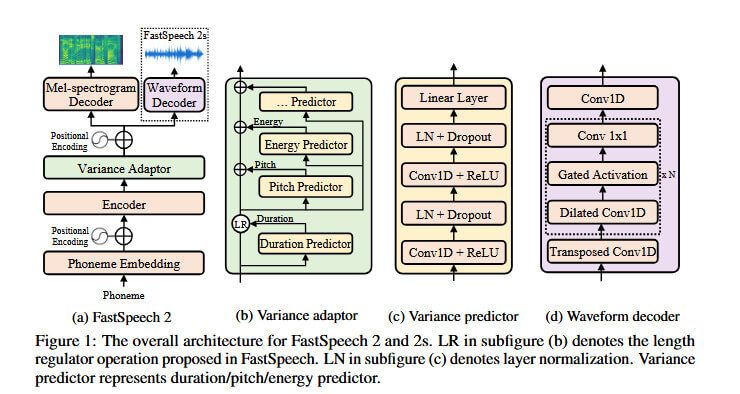
在FastSpeech中可以看到音素(Phoneme)经过音素嵌入层,再经过位置编码进入N层的前馈变换器块。之后经过长度调节器(Length Regulator)后,与位置编码一起再经过N层的前馈变换器块(FFT Block)后,经过线性层输出梅尔频谱图。
而FastSpeech2中的变化是将第1个FFT Block修改为编码器(Encoder),经过方差适配器(Variance Adaptor),叠加位置编码后输出到梅尔频谱解码器(Mel-spectrogram Decoder)和声波解码器(Waveform Decoder)中。
对于代码的复现,可以参考Paperswithcode,我们可以搜索相关的paper,查看其是否有一些代码、数据集及结果的测评。
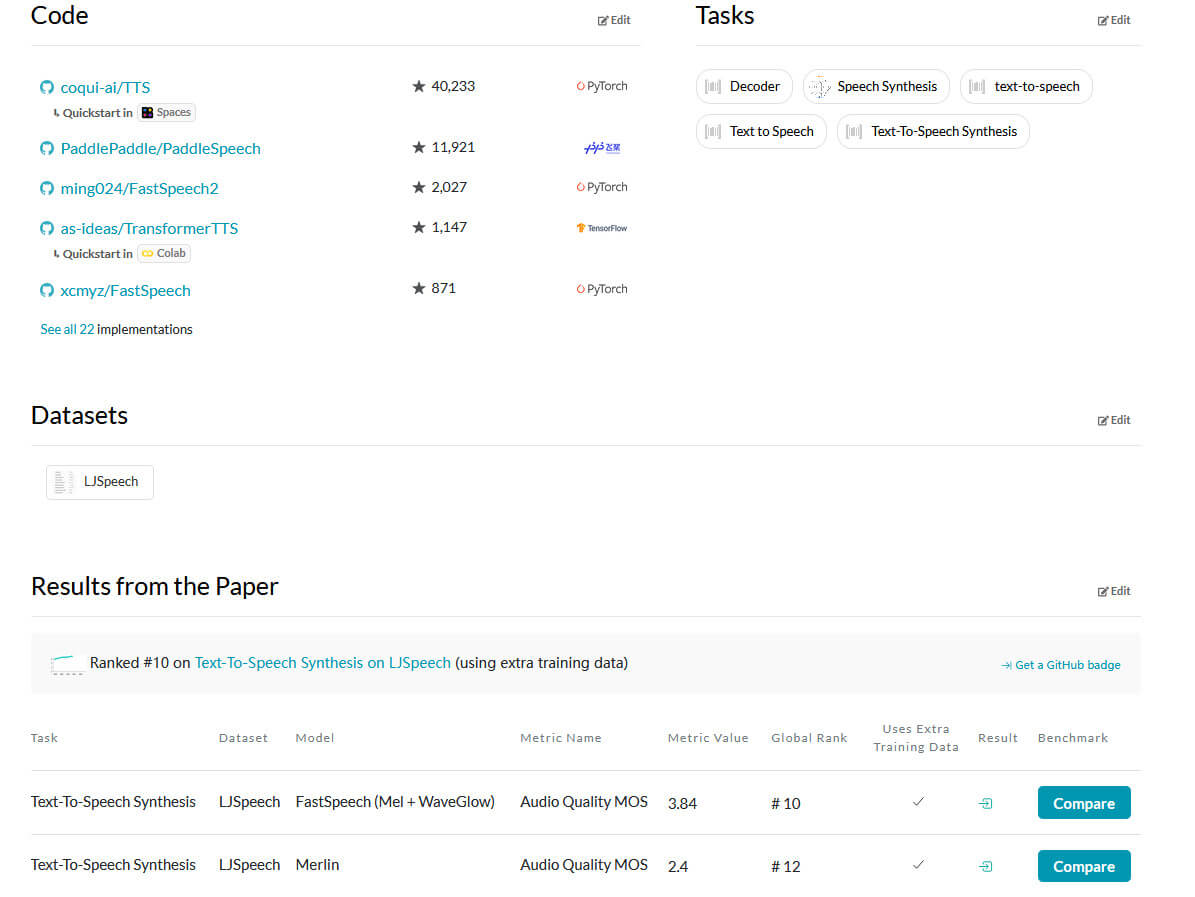
从上图可以看到,FastSpeech有多个实现,根据框架不同选择对应的实现。而数据集只有LJSpeech。
在FastSpeech2的实现ming024/FastSpeech2中有如下的代码:
class FastSpeech2(nn.Module):
""" FastSpeech2 """
def __init__(self, preprocess_config, model_config):
super(FastSpeech2, self).__init__()
self.model_config = model_config
self.encoder = Encoder(model_config)
self.variance_adaptor = VarianceAdaptor(preprocess_config, model_config)
self.decoder = Decoder(model_config)
self.mel_linear = nn.Linear(
model_config["transformer"]["decoder_hidden"],
preprocess_config["preprocessing"]["mel"]["n_mel_channels"],
)
self.postnet = PostNet()
正好对应之前的网络结构。
总体而言,对于论文的阅读,需要对基础有一定的了解,能够举一反三。论文中可能会提出一些很新颖的名词,而实际上就是你熟悉的某些方法。不要被他吓到了。

