前言
如果非要说什么的话,那就是用OCR来识别文件内容其实是把问题复杂化的表现,但是应用场景还是有那么一些,比如古籍的扫描后文字的识别,毕竟人工成本还是比较高的。 先来看个自拍的图片:

可以很清楚看到其中的图片,下面开始编写相关的代码:
from paddleocr import PPStructure
table_engine = PPStructure(show_log=True)
img_path="20250422094717.jpg"
result = table_engine(img_path)
for line in result:
if line["type"] == "Table":
html = line["res"]["html"]
其中html变量就是识别出来的HTML代码,其效果如下:

我们为其添加一个像素的边框后可以看到其内容识别的并不全。预计是没有进行预处理的,导致其版面识别就有问题,自然影响后续内容的识别。
识别截图
接着来看一张从PDF中的截图,这张图片相对来说比较干净,因为只有黑白两种颜色,是很适合OCR进行处理的。
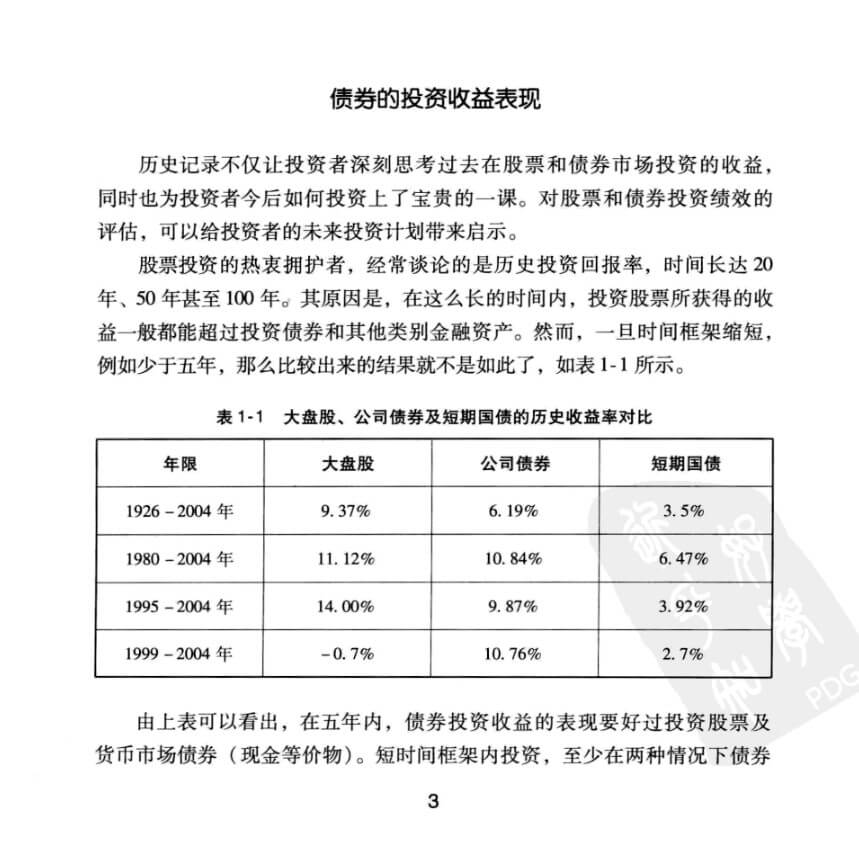
其效果如下:
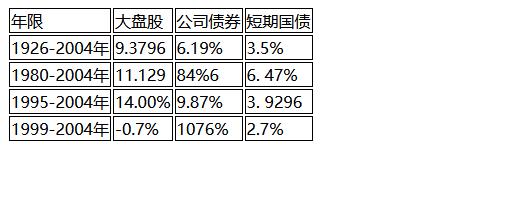
可以看到其成功将表格识别出来了,另外最后一行中10.76%的值漏掉了点号,因此还需要后处理进行校正。
如果喜欢这篇文章或对您有帮助,可以:[☕] 请我喝杯咖啡 | [💓] 小额赞助

