MoE是大模型中的常见的术语,其是Mixture-Of-Experts的缩写,即专家混合。如果读者对机器学习有所了解的话,应该很容易理解其实MoE就是个换汤不换药的东西。
在传统机器学习中有集成学习(Ensemble Learning)这个策略。说个大家都通俗易懂的方式,那就是俗语"三个臭皮匠,赛过诸葛亮"。毕竟个人的能力都是有限的,而多个人作为团队作战则可以弥补彼此的劣势,从而最大程度发挥优势。
在机器学习之前,一般都会经历专家模型这个阶段。而MoE中选择是选择多个专家的方式,意思是听从多个专家的意见,然后自己总结归纳作出决策。而总结归纳这个过程,一般会采用均值或加权的方式。
MoE作为一种由专家模型和门控模型组成的稀疏门控制的深度学习技术,由多个子模型(称之为专家)组成,每个子模型都是一个局部模型。其结构如下图所示:
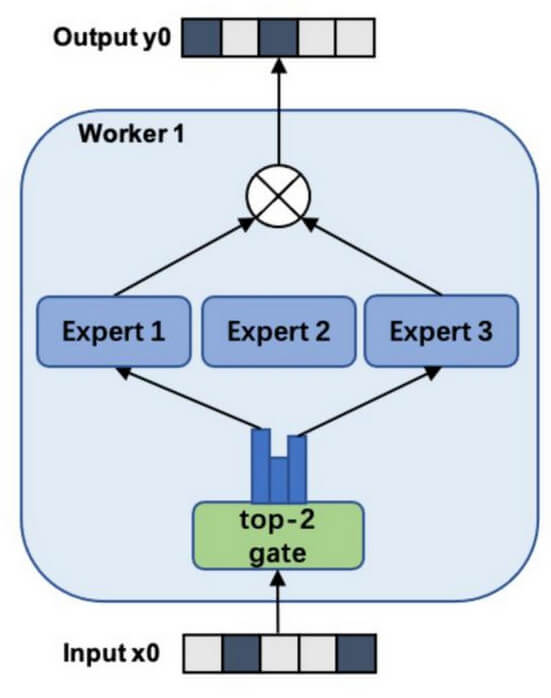
其中门控模型可以选择性让输入特征经过/激活某些子模型,从而减少训练的计算量。通过稀疏激活控制方式,通过Top-K机制筛选权重最高的专家来减少计算量。其通过激活少量专家,大幅降低推理和训练成本。
可以看到AI中的一些概念还是源自生活的实践。
如果喜欢这篇文章或对您有帮助,可以:[☕] 请我喝杯咖啡 | [💓] 小额赞助

