LLaVA模型使用最简单的模型结构,最少的数据却达到最好的效果。该模型名称是Large Language and Vision Assistant的缩写。
作者通过Prompt工程,通过提供图片的描述信息和目标检测信息,用纯文本输入,用GPT 4生成更丰富更真实的数据,通过COCO数据集构造对话(58K)+详细描述(23K)+复杂推理)77K)共158K的数据集。
其图像编码器使用的是ViT-L/14,而LLM使用的是Vicuna。其网络结构如下图所示:
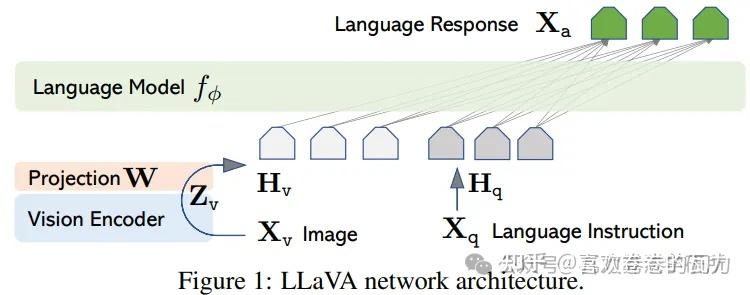
而多模态融合采用最简单的线性映射层。图片经过ViT后得到图片特征,经过线性投射后得到视觉token,再与文本token拼接从而形成多模态的输入。
其训练过程可以分为两阶段:
- 特征对齐的预训练
- 端到端微调
在第1阶段,冻结视觉编码器和LLM,仅训练线性投射层。采用CC3M数据集筛选至595K对图像-文本对,进行简单描述图片问答。 而在第2阶段,冻结视觉编码器,训练线性投影层和LLM,使用GPT 4生成158K视觉指令跟随数据。
而LLaVA-1.5在LLaVA基础上进行更进一步的改进,其实1个13B模型,采用120万公开数据集,使用8个A100训练1天,在11个基准任务取得SOTA。在网络结构方面,将一层的线性层替换为了2层。
参考视频:
如果喜欢这篇文章或对您有帮助,可以:[☕] 请我喝杯咖啡 | [💓] 小额赞助

