前言
以下是YOLO系列各个版本的发布时间及对应论文概述。
| 网络架构 | 发布时间 | 论文标题 |
|---|---|---|
| YOLOv1 | 2015.6 | You Only Look Once: Unified, Real-Time Object Detection |
| YOLOv2 | 2016.12 | YOLO9000: Better, Faster, Stronger |
| YOLOv3 | 2018.4 | YOLOv3: An Incremental Improvement |
| YOLOv4 | 2020.4 | YOLOv4: Optimal Speed and Accuracy of Object Detection |
我们可以将YOLO系统按照时间顺序划分为3个阶段:
- 开创纪元(2015-2016)
- YOLO v1(2015):提出"回归式检测"新范式,将检测任务转化为单次网格预测,实现155 FPS的实时性能
- YOLO v2(2016):引入锚框聚类、多尺度训练等创新,mAP提升10个百分点,支持9000类物体检测
- 技术爆发(2017-2020)
- YOLO v3(2018):采用Darknet-53骨干网络,引入FPN结构,在保持速度优势下精度媲美两阶段算法
- YOLO v4(2020):集成CSPNet、SAM模块等前沿技术,首次在COCO数据集实现43.5% AP@50:95
- 工业革命(2021至今)
- YOLO v5:开源社区驱动的工程化改进,支持TensorRT加速
- YOLOv6/v7:美团/旷视等企业的工业级优化,推理速度突破200FPS
- YOLOv8(2023):加入可编程梯度信息(PGI)技术,实现精度-速度-易用性三重突破
这里只介绍前3个版本的内容。
YOLOv1
YOLO的网络结构的灵感来自图片分类的GoogLeNet。网络有24个卷积层,紧接着是2个全连接层。其网络架构图如下:
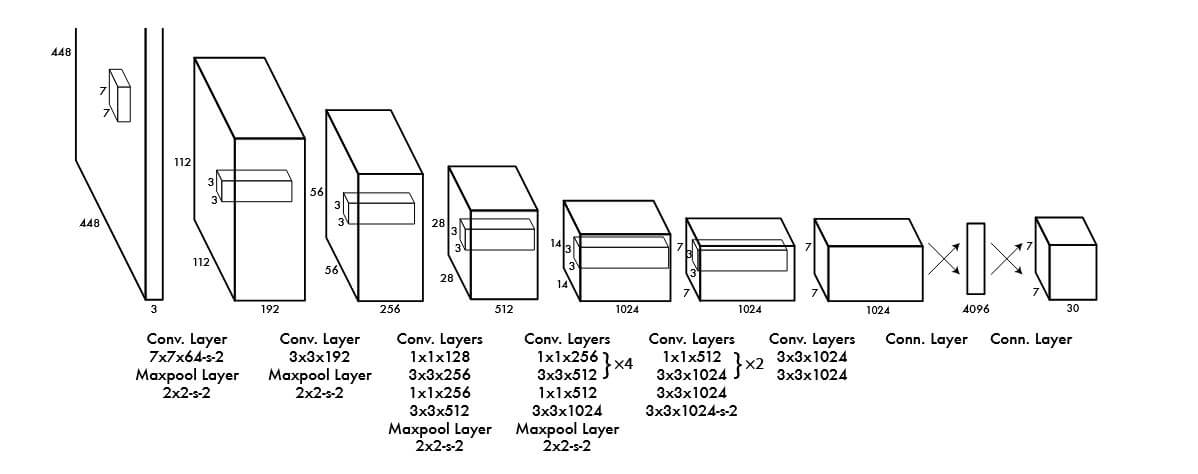
模型输入的图像尺寸为448x448x3,而最终输出为7x7x30的张量。通过公式SxSx(Bx5+C)计算得到,其中S=7(网格),B=2(边框数),C=20(类别数,采用PASCAL VOC 2007与2012数据集)。
其思想是通过将输入图片划分为固定大小SxS的格子(grid cells),每个网格单元负责对落在该单元内的物体进行预测,并一次性预测所有格子所含目标的边界框、定位置信度以及所有类别概率向量。简而言之,当一个物体的边界框中心点落在某个网格单元内,该单元负责预测该物体。每个网格单元预测B个边界框,每个框包含坐标和置信度,但最终采用与真实框(Ground Truth)IOU最高的预测框作为有效输出。
而置信度的定义为
$$ \text{Pr}(\text{Object})\ast\text{IOU}_{\text{pred}}^{\text{truth}} $$
如果网格单元内没有物体则置信度分数为0。每个边界框由5个预测值组成,分别为x,y,w,h和置信度。每个网格单元也预测C个条件类概率$\text{Pr}(\text{Class}_{i}\mid\text{Object})$。该概率表示网格单元包含物体的条件概率。
YOLOv2
在YOLOv2中完全移除了之前的全连接层,并引入BN层(Batch Normalization)加速收敛,另外使用锚框(Anchor)来预测边界框。与v1不同的是,v2版本输入的图片尺寸为416x416x3,主要是为了能在特征图中得到奇数的位置。对于输出13x13的特征图,其32倍上采样后正好是416。
另外其使用k均值聚类自动来划分先验框,其中k=5时效果较好。
而在网络结构上,使用Darknet-19替换了之前的GoogLeNet网络,该网络具有19个卷积层和5个池化层。其网络结构如下图所示:
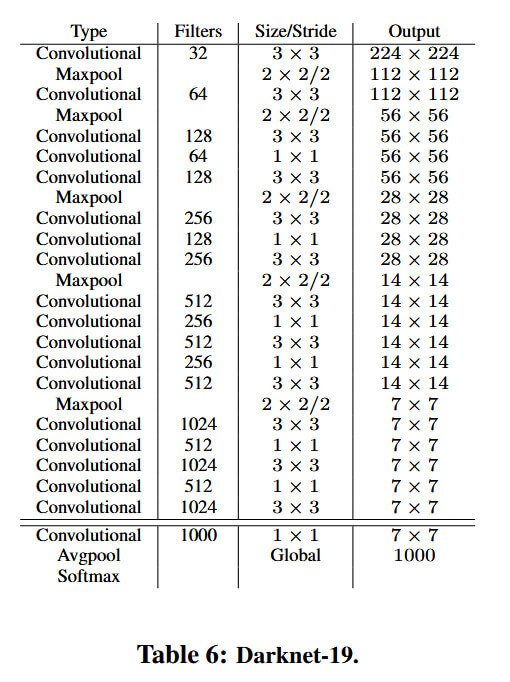
并引入了Passthrough层,通过将浅层26x26特征图与深层13x13特征图进行拼接,保留细节信息从而提升小目标检测能力。而在训练时采用多尺度方式,每10个batch随机切换输入尺寸(从320x320至608x608),增强模型对不同尺度目标的适应性。
YOLOv3
YOLOv3最大的改进是网络结构,使其更适合小目标检测。另外特征做的更细致,通过融入多持续特征图信息来预测不同规格物体。另外,先验框更丰富了,一共有3种比例,每种3个规格,故有9种。对softmax进行改进使其可以预测多标签任务。 其网络结构如下图所示,通过跳跃连接解决深层网络梯度消失问题:
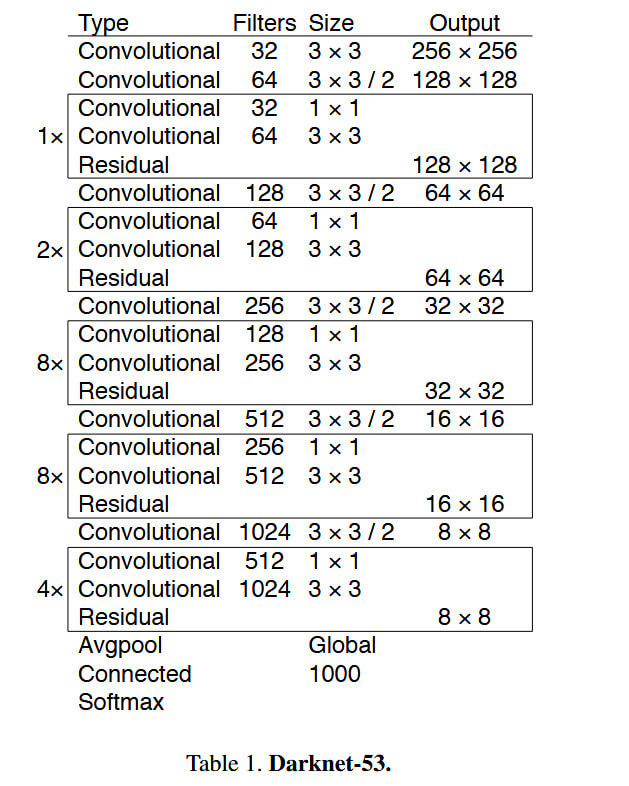
其引入FPN模块,通过三尺度进行特征融合。新增52x52高分辨率特征图用于小目标检测,结合26x26(中目标)、13x13(大目标)形成金字塔结构。深层特征上采样后与浅层特征拼接,融合语义与细节信息。
损失函数(Loss function)
损失函数包括:
- classification loss,分类损失
- localization loss,定位损失(预测边界框与Ground Truth之间的误差)
- confidence loss,置信度损失(框的目标性)
总的损失函数为classification loss+localization loss+confidence loss。

